
Phishing remains one of the most fraudulent tricks that can be found in malicious email traffic. In this type of attack, a recipient will receive an email, for example, disguised as a message from a well-known company that requires them to follow a link and login to a service or enter bank card details on a fake web page.
In 2019, Kaspersky’s anti-phishing system identified 467 million attempted transitions to phishing websites. Nearly one-in-seven of our users has faced this threat.
Fortunately, although phishing techniques are constantly developing, detection methods are advancing just as quickly. Confrontation from attackers will persist as long as their attempts are profitable. Therefore, phishing protection mechanisms must work to decrease the response time to new scam techniques to make attacks as unprofitable as possible.
How Phishing Has Evolved and Ways of Detecting it
About 10 years ago, manually-created dictionaries were used to detect phishing in email traffic. They described all of the possible variants that phishing texts may include. Later, heuristics started to appear in the arsenal of detection technologies. Heuristics mean searching for signs that indicate a message’s nature and how it may be dangerous. For example, if there is a link in a malicious email, then the indicator could be an unprotected protocol such as http, instead of https or the recipient’s email being present inside the link. Another common sign is if the message looks like it was sent from a well-known company.

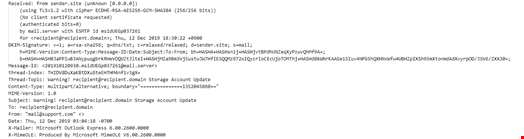
Analysis of email headers is another common detection technique. A header contains information about the email, its sender and route to the recipient, including date of creation, ID number, encoding type, mailing address and IP address. It is visible in a message’s properties. Analysis of headers helps cybersecurity specialists identify suspicious senders.
The presence of only one phishing indicator doesn’t necessarily help us identify and guarantee if the message is malicious or not. Instead, we look for sets of these indicators which are combined into signatures that can uniquely identify if a message is malicious.
However, attackers do not stand still. Today, they are increasing the amount of attacks being carried out by disguising their malicious messages as emails from new online services, exploiting popular events, for example, premieres of new television series, big sport or music events, and of course, the coronavirus pandemic.
For example, in the first quarter of 2020, we found many cases of phishing emails that had been circulated with a request to transfer money to combat COVID-19, as well as fake emails from the World Health Organization that encouraged recipients to find out about the latest recommendations against the virus by signing into a fake version of the WHO website.
In addition to the new opportunities for mass email, the message content and how they are disguised have become more complicated. Texts and headings have become more variable, phishing pages can use the secure https protocol, and mail-outs can be sent using botnets. As a result, malicious messages have become much more difficult to detect. In the past, after catching a single phishing email, a security product could quickly create a signature that would block all incoming mail from this sender. However, scammers can now use many botnets to automatically create thousands of text samples and heading variations.
To protect users from such tricky attacks, we need technology that can quickly detect new types of phishing emails through automation. This technology uses statistics and machine learning, which allows it to automatically extract the necessary information to detect and block phishing, as well as quickly train and retrain itself as needed. In this article, we will talk about one of the technologies designed to detect email phishing based on message headers and content analysis.
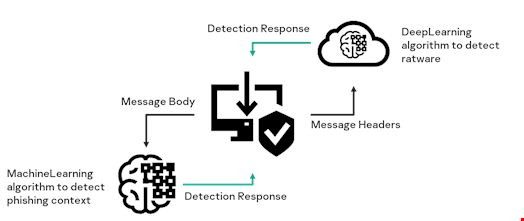
Technology Scheme
The image above shows the general principle of this technology. It is an ensemble of two machine learning algorithms that analyze different elements of messages. Together, they provide a solution that can automatically detect and block phishing without false positives.
The first algorithm (a deep learning algorithm to detect ratware), or the classifier, is located in a cloud service, to which the product is connected upon installation on the user’s device. It processes email headers using a deep neural network to detect signs of ratware – software that automatically generates and sends mass messages.
The second classifier (a machine learning algorithm to detect phishing context) works on the client’s device and determines phishing vocabulary in the message body.
How it Works and Why There Are Two Classifiers
Before moving on to describing the technology, let’s look at how the email transmission works and what attackers do to circumvent email security systems.
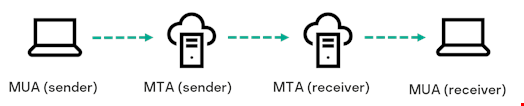
According to the above image, a Mail User Agent (MUA) is needed to create and send an email, for example, Microsoft Outlook. An MUA is responsible for generating the message and sending it to the Mail Transfer Agent (MTA) for further routing. In addition to fields like the message body, subject and recipient addresses, which are filled in by users, the MUA puts down the necessary headers.
In order to circumvent mail security systems, attackers often use their own MUA, which is a part of ratware. This makes it possible to easily create an email at their request. By greatly varying the headers, they achieve maximum diversity in their samples. This makes grouping and blocking such emails by signatures an extremely difficult and time-consuming task.
Classifier Number One
Considering the tools and approach for malicious emails we mentioned above, the necessary task in terms of protection is not to describe a specific type of phishing email with signatures, but to create a tool that can detect ratware traces based on headers. The first classifier is used for this.
The classifier is based on a deep neural network. It is regularly trained on the basis of hundreds of millions of metadata records, that are headings obtained from the statistics of spam emails detected by Kaspersky products. Neural networks extract non-trivial features from the statistics to detect suspicious headers in the email.
The image below illustrates exactly what features the algorithm looks for. On the left is a real email from PayPal, on the right is a fake. One of the required headers for an email is Message-Id, a unique identifier for a message that has a specific look for various MUAs. The absence of a domain, a random sequence of characters and registers are immediately evident when you look at the differences between the original message and the fake.
These, as well as other traces, are left by scammers on various email headers. The model learns to recognize the combinations of traces that prove that the email is malicious.

The adding of this classifier in the cloud service allows us to use the high computing capabilities of the server, reduce calculations on the user computer and instantly update the model based on new data.
Classifier Number Two
One of the main distinguishing elements of phishing attacks is how they can evoke human emotions and concerns. Obviously, a person who is worried about their bank account or a long-awaited parcel is more likely to click a link in an email and fill in all the proposed fields.
To achieve the desired emotional effect, attackers use emotive language in their text. For example, in phishing emails you can often see calls to action such as “download attachment” or “click this link,” a notification of a serious problem like “your parcel couldn't be delivered” or “your account will be suspended indefinitely,” and phrases related to finance such as “reverse the payment,” or “view invoice. The image below shows some examples of emails with underlined phishing phrases.
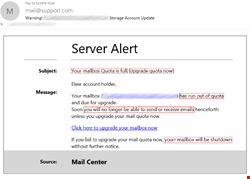
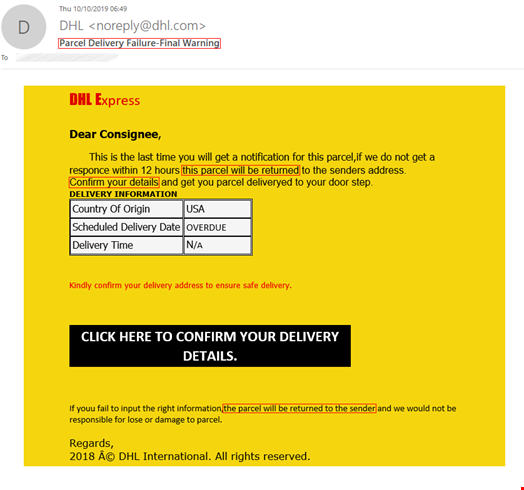
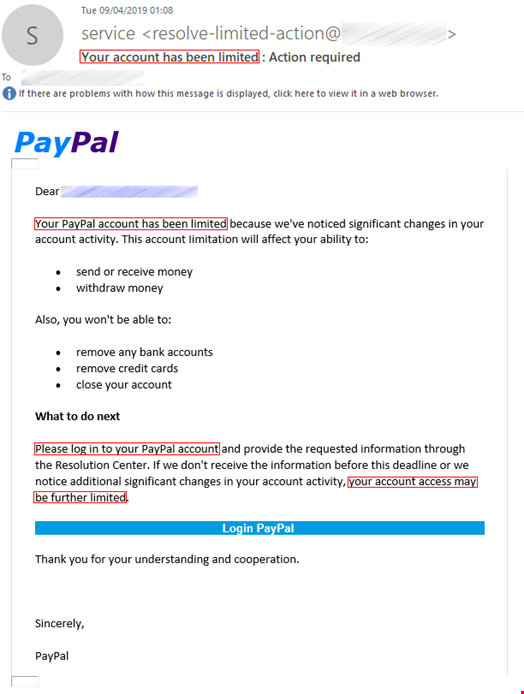
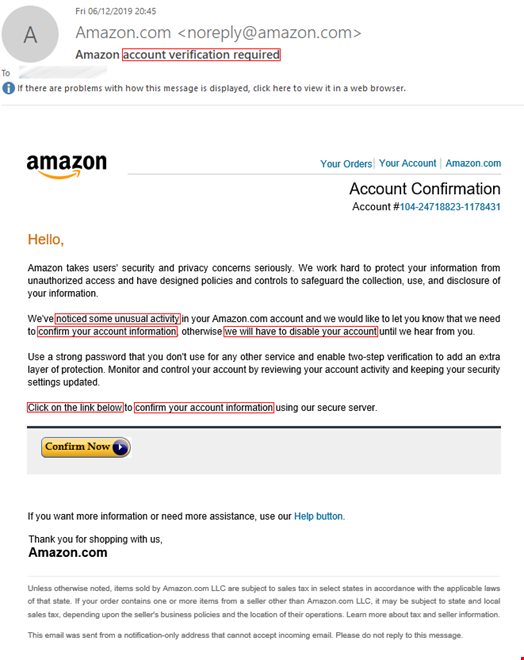
Texts in phishing emails are more elaborate and do not contain explicit triggers, unlike, for example, spam texts. The latter use vocabulary from very specific areas, such as pharmaceuticals, which are easy to detect. A Viagra advert is a spam classic. Phishing texts vary greatly and change over time, which makes them difficult to be captured by signature methods alone and do not allow detection solutions to make a verdict based solely on the text whether the email is malicious or not.
The second classifier uses a model to exactly analyze incoming messages and detect phishing phrases.
During the training period, the model analyzes many examples of phishing emails: it splits them into separate phrases and assigns weight to each phrase depending on its potential for phishing activity, or how common it is among phishing communications. For example, the phrase “Best regards” will carry a low weight because it has no signs of phishing and is often used in legitimate messages. The phrases that call for payment, following a link and entering data will have more weight, because they are specifically found in phishing emails.
As a result of this weighting, the model gains a whole category of words and phrases which will then be considered as suspicious if found in a message. This category is passed to the classifier, which is located on the client’s device (see image three). The classifier uses this category as a reference and based on this, it can decide whether the messages arriving in the client’s mailbox contain phishing context.
This method is conceptually simple, but highly effective, because, firstly, the algorithm of the model is transparent, or interpretable - it is easy to understand by the weight why the model made its verdict. And secondly, it quickly learns and quickly updates. This helps the model maintain its performance and quality of detection due to the evolution of phishing texts over time.
What is the Result?
By combining the classifiers that inspect the content of an email and its header metadata, we achieved a new technology that can detect and confidently block phishing emails in real time. The verdict of only one of the two classifiers is not enough to define if a message is phishing. It is necessary for the verdicts to coincide – this allows the technology to more accurately identify malicious messages and minimize the likelihood of a false positive.
What is the advantage of this solution? Firstly, this allows us to be much more proactive. The technology is able to detect phishing techniques that have not been seen before. This distinguishes the solution from popular methods based on the signature approach, when you first need to see the sample in order to block it in the future.
Secondly, it is a fully automatic solution. The technology independently learns from new collections of statistical data, which allows the speed of response and detection of malicious emails to increase.
Thirdly, it can detect non-trivial patterns. Thanks to the model architecture and the large amount of data available for training, it is able to extract complex patterns. For example, this includes strange sequences of characters or registers in headers that cannot be found manually.
We continue to improve the technology and plan to add other classifiers that will analyze more message parameters. In its current form, as part of the solutions for protecting mail servers and the Microsoft Office 365 application, the technology has already been used to help increase the detection rate of the most sophisticated phishing emails.
Explore Kaspersky Security Solutions for Enterprise to predict, prevent, detect and respond to cyber-attacks.
