

Based on an August 2020 report by Interpol, more people have been spending time online since the start of the coronavirus pandemic, which has resulted in increased cybercrime. UK Finance also claimed remote banking fraud losses soared by 21% to reach 80 million pounds during the first half of 2020. Online fraud is on the rise.
ING reported the following in their 2019 Annual Report: “Technology can help us deal with these risks by improving customer due diligence processes and the prevention, detection, quality and speed of response to financial economic crime. For example, we developed a virtual alert handler that uses artificial intelligence to better detect suspicious transactions and customer behaviors, … An AI-based anomaly detection tool went live in September, which is used to uncover suspicious transactions in the clearing and settlement process between banks.”
Criminals are persistently finding new ways to circumvent measures put in place to prevent fraud, making their activities difficult to detect. Thus, it is difficult for advanced machine learning models to be trained from available data because fraudulent patterns are not only scarce but also change rapidly. Below, we explore how data science can be used to identify credit card fraud.
Our case study draws on the Credit Card Fraud Detection Kaggle dataset which contains more than 284,000 credit card transactions performed by EU cardholders in September 2013. Each transaction is described by 30 features: 28 principal components pulled from the original data, the transaction amount, and the date. The 28 principal components hide sensitive cardholder data. Each transaction is assigned a class label: legitimate (0) and fraudulent (1).
Most of the transactions in the dataset are legitimate; only a very small portion — 492, or 0.2% — are fraudulent. This disproportion does not allow us to train supervised machine learning models successfully, given the limited number of available examples for the fraud class. If we consider that most datasets with credit card transactions are unlabeled or that fraudulent transactions cannot be reliably manually identified, the chances of applying a supervised machine learning model successfully dwindle further. This is where outlier detection techniques can be useful. Here, we experiment with several different outlier detection techniques.
- Quantile-based: Box plot
- Distribution-based: Z-score
- Cluster-based: DBSCAN
- Neural autoencoder
- Isolation forest
Of the 492 fraudulent transactions, we used 80 in a validation set to optimize the parameters involved in the techniques, such as thresholds, and 20 as part of a test set. A corresponding number of the more numerous legitimate transactions was added to both validation and test sets. Performances, in terms of Recall and Precision on the test set, are reported in Fig. 1.
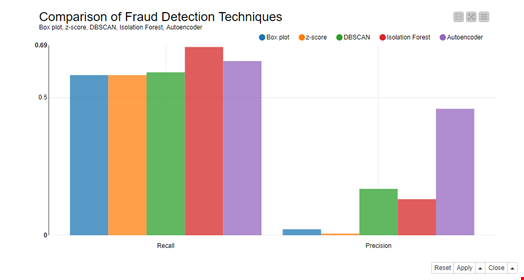
The number of false positives is incredibly high for the first two techniques, box plot and z-score, as seen from their Precision percentage. This means that to detect some 60% of fraudulent actions, most transactions are labeled as fraud alarms. Not very useful!
Producing fewer false positives yet discovering at least half of the frauds, the DBSCAN, autoencoder, and isolation forest techniques are slightly more discriminant. The neural autoencoder performed quite well — after we realized that ReLU activation functions are not recommended for autoencoder hidden units, but rather sigmoid activation functions should be preferred. The DBSCAN algorithm is sensitive to its configuration but also performed well after parameter optimization.
Note: The problem of false positives will never disappear since an outlier detection technique is designed to detect what is unusual. They will frequently get mixed up with legitimate transactions unless you have a very separate pattern for fraudulent transactions — one that rarely changes. Also remember that fraudsters are doing their very best to make their fraudulent transactions look as much like legitimate transactions as possible. So, when applying these strategies, we must be prepared to face a fair number of false positives, i.e., fraud alarms that lead to nothing.
In conclusion, we could measure the performance of all implemented outlier detection techniques, in terms of recall and precision, using the few credit card transactions in the dataset labeled as fraudulent. The best compromise between number of frauds discovered (recall) and number of true alarms (precision) came from the neural autoencoder. Because of the very nature of an outlier event and, therefore, of an outlier detection technique, none of the strategies were immune from the false positives. At times, you have to work with the data that’s available: Lacking a labeled dataset, an outlier detection technique may be the best data science choice.